RANSAC
Published: 2020-03-10 | Lastmod: 2020-03-15
在MSCKF的前端跟踪中,会使用RANSAC方法估计最优的平移量,可参考 MSCKF前端跟踪。
算法基本思想和流程 #
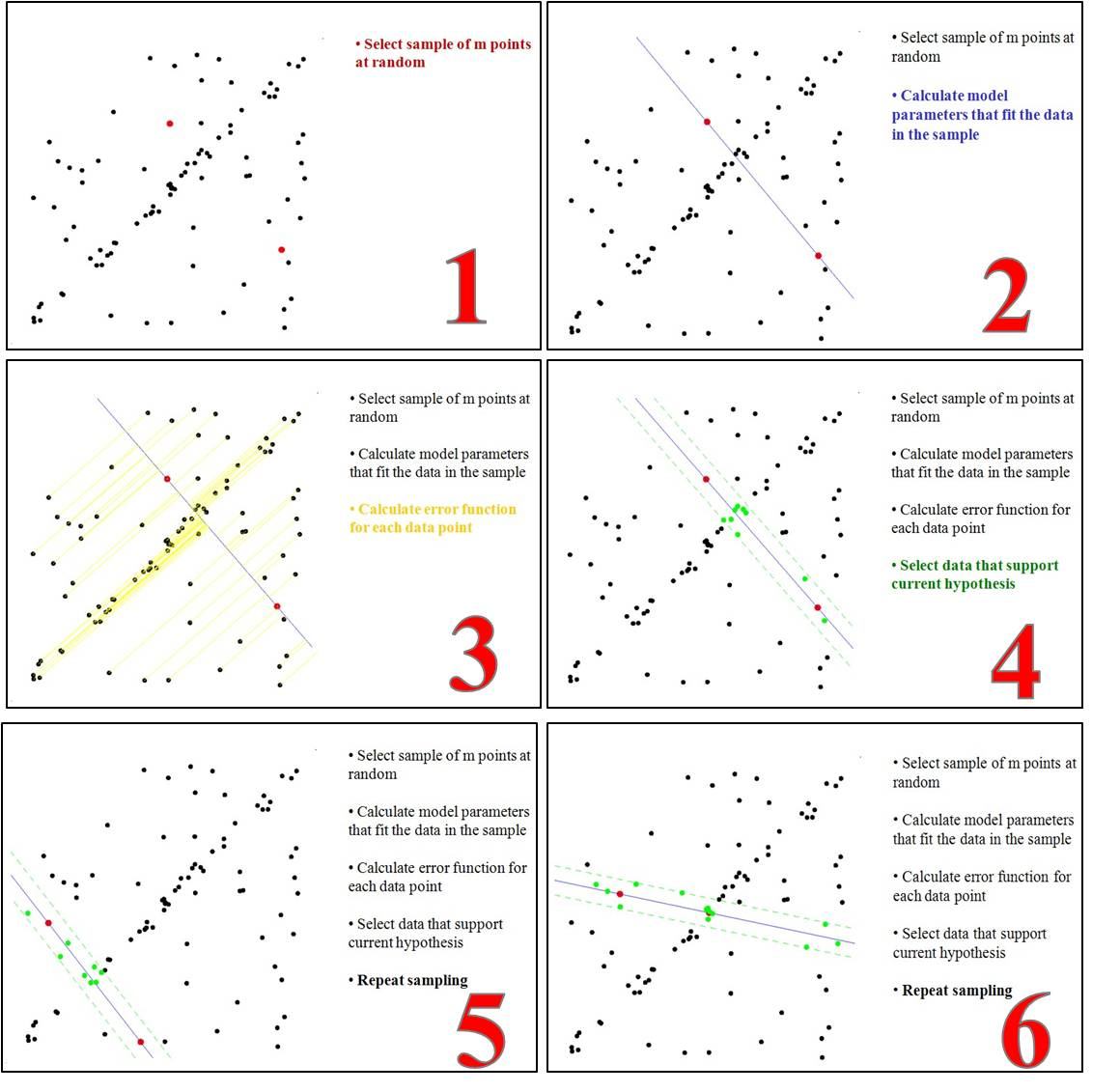
RANSAC是通过反复选择数据集去估计出模型,一直迭代到估计出认为比较好的模型。
具体的实现步骤可以分为以下几步:
- 选择出可以估计出模型的最小数据集;(对于直线拟合来说就是两个点,对于计算Homography矩阵就是4个点)
- 使用这个数据集来计算出数据模型;
- 将所有数据带入这个模型,计算出“内点”的数目;(累加在一定误差范围内的适合当前迭代推出模型的数据)
- 比较当前模型和之前推出的最好的模型的“内点“的数量,记录最大“内点”数的模型参数和“内点”数;
- 重复1-4步,直到迭代结束或者当前模型已经足够好了(“内点数目大于一定数量”)。
算法输入 #
- 判断样本是否满足模型的误差容忍度t。t可以看作为对内点噪声均方差的假设,对于不同的输入数据需采用人工干预的方式预设合适的门限,且该参数对RANSAC性能有很大的影响;
- 随机抽取样本集S的次数。该参数直接影响余集SC中样本参与模型参数的检验次数,从而影响算法的效率,因为大部分随机抽样都受到外点的影响;
- 表征得到正确模型时,一致集S*的大小N。为了确保得到表征数据集P的正确模型,一般要求一致集足够大;另外,足够多的一致样本使得重新估计的模型参数更精确。
- 算法的迭代次数k。
- 适应于数据的模型model。
- 随机在样本抽样的数目n。
迭代次数推导 #

例子 #
Next: Kd Tree
Previous: 大比例尺地形图测绘